One minute
Memcached
简介Memchahed
- Memcached是高性能分布式内存缓存服务器,它通过缓存数据库查询结果,减少对数据库的访问次数以提高动态Web应用的速度,提高可扩展性。
- Memcached的API使用32位元的CRC(循环冗余校验)校验,计算键值后,将资料分散在不同的机器上,当表格满了以后,接下来新增的资料会以LRU机制替换掉。
- Memcached基于一个存储键/值对的Hashmap。其守护进程是用C写的,但是客户端可以用任何语言来写,并通过mencached协议与其守护进程通信。
Memcached分布式算法
余数哈希
- 根据服务器的台数的余数进行分散。求得键的哈希值,再除以服务器的台数,根据余数选择服务器。
缺点:
- 当添加或移除服务器时,缓存重组代价太大。当添加服务器要进行重哈希,会导致原来的服务器序号变了,按原来的逻辑寻找数据就会找不到,访问数据Memcached命中率下降,那么就会增加数据库服务器的负载。
一致性哈希
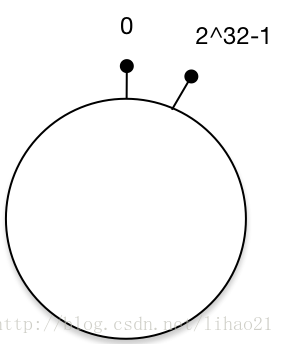
- 一致性hash算法通过一个叫作一致性hash环的数据结构实现。这个环的起点是0,终点是2^32 - 1,并且起点与终点连接,环的中间的整数按逆时针分布,故这个环的整数分布范围是[0, 2^32-1]
- 首先求出memcached服务器(节点)的哈希值,并将其配置到0~2^32-1的圆(continuum)上。
- 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2^32-1仍然找不到服务器,就会保存到第一台memcached服务器上。
在Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。
Memcached的数据清除算法
LRU。每个slab会维护一个队列,刚插入的数据在队头,经常get的数据也会移动到队头,这样较老或者访问较少的数据相对都留在队尾。
该算法从队尾开始淘汰,当slab分配不到足够的内存时,首先会检查队尾是否有过期数据。如果有的话会直接将其覆盖为新的对象,如果没有,会开始淘汰队尾的对象。
Slab是一个内存块,它是memcached一次申请内存的最小单位。Slab的大小固定为1M(1048576 Byte),一个slab由若干个大小相等的chunk组成。每个chunk中都保存了一个item结构体、一对key和value。
描述一下Memcacehd的工作流程
- 先检查客户端的请求数据是否在memcached中,如有,直接把请求数据返回,不再对数据库进行任何操作;
- 如果请求的数据不在memcached中,就去查数据库,把从数据库中获取的数据返回给客户端,同时把数据缓存一份到memcached中(memcached客户端不负责,需要程序明确实现);
- 每次更新数据库的同时更新memcached中的数据,保证一致性;
- 当分配给memcached内存空间用完之后,会使用LRU(Least Recently Used,最近最少使用)策略加上到期失效策略,失效数据首先被替换,然后再替换掉最近未使用的数据。
Memcached 和 Redis的区别
- Redis不仅仅支持简单的k/v类型的数据,同时还提供string(字符串)、list(链表)、set(集合)、zset(sorted set –有序集合)和hash(哈希类型)等数据结构的存储。
memcache支持简单的数据类型,String。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中
redis的速度比memcached快很多
Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的IO复用模型。
有持久化需求或者对数据结构和处理有高级要求的应用,选择redis,其他简单的key/value存储,选择memcached。 对于两者的选择需要要看具体的应用场景,如果需要缓存的数据只是key-value这样简单的结构时,则还是采用memcache,它也足够的稳定可靠。 如果涉及到存储,排序等一系列复杂的操作时,毫无疑问选择redis。
Read other posts